Hadoop is an apache open source software (java framework) which runs on a cluster of commodity machines. Hadoop provides both distributed storage and distributed processing of very large data sets. Hadoop is capable of processing Informatica Big Data of sizes ranging from Gigabytes to Petabytes.
Hadoop architecture is similar to master/slave architecture. The architecture of hadoop is shown in the below diagram:
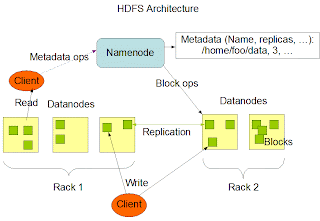
Hadoop Architecture Overview:
Hadoop is a master/ slave architecture. The master being the namenode and slaves are datanodes. The namenode controls the access to the data by clients. The datanodes manage the storage of data on the nodes that are running on. Hadoop splits the file into one or more blocks and these blocks are stored in the datanodes. Each data block is replicated to 3 different datanodes to provide high availability of the hadoop system. The block replication factor is configurable.
The major components of hadoop are:
Hadoop architecture is similar to master/slave architecture. The architecture of hadoop is shown in the below diagram:
Hadoop MRV1 Architecture:

Hadoop Architecture Overview:
Hadoop is a master/ slave architecture. The master being the namenode and slaves are datanodes. The namenode controls the access to the data by clients. The datanodes manage the storage of data on the nodes that are running on. Hadoop splits the file into one or more blocks and these blocks are stored in the datanodes. Each data block is replicated to 3 different datanodes to provide high availability of the hadoop system. The block replication factor is configurable.
Hadoop Components:
The major components of hadoop are:
- Hadoop Distributed File System: HDFS is designed to run on commodity machines which are of low cost hardware. The distributed data is stored in the HDFS file system. HDFS is highly fault tolerant and provides high throughput access to the applications that require big data.
- Namenode: Namenode is the heart of the hadoop system. The namenode manages the file system namespace. It stores the metadata information of the data blocks. This metadata is stored permanently on to local disk in the form of namespace image and edit log file. The namenode also knows the location of the data blocks on the data node. However the namenode does not store this information persistently. The namenode creates the block to datanode mapping when it is restarted. If the namenode crashes, then the entire hadoop system goes down. Read more about Namemode
- Secondary Namenode: The responsibility of secondary name node is to periodically copy and merge the namespace image and edit log. In case if the name node crashes, then the namespace image stored in secondary namenode can be used to restart the namenode.
- DataNode: It stores the blocks of data and retrieves them. The datanodes also reports the blocks information to the namenode periodically.
- JobTracker: JobTracker responsibility is to schedule the clients jobs. Job tracker creates map and reduce tasks and schedules them to run on the datanodes (tasktrackers). Job Tracker also checks for any failed tasks and reschedules the failed tasks on another datanode. Jobtracker can be run on the namenode or a separate node.
- TaskTracker: Tasktracker runs on the datanodes. Task trackers responsibility is to run the the map or reduce tasks assigned by the namenode and to report the status of the tasks to the namenode.
The blog was absolutely fantastic! Lot of information is helpful in some or the other way. Keep updating the blog, looking forward for more content...Great job, keep it up
ReplyDeleteOracle Fusion Financials Online Training
Oracle Fusion HCM Online Training
Oracle Fusion SCM Online Training